Introduction
Background and Challenges
Software systems have become a crucial part of business and commerce in the modern world. Consequently, software quality has become fundamental in ensuring the proper functioning of the systems and minimizing development and maintenance costs. The quality of software should be guaranteed throughout the entire life cycle of software development, which points towards detecting errors earlier during development. Jennifer Tidwell wrote, “Software, after all, is merely a means to an end for the people who use it. The better you satisfy those ends, the happier those users will be.” (Tidwell 1).
Software technology plays an important role in the lives of human beings and society. As the expectations for even better products are growing day by day, the software systems are turning out to be more and more challenging to build. Software development professionals happen to be more in demand. Consequently, to be at par with the growing demand, new techniques and devices are being developed to build better software and at the same time for their maintenance. According to Hong Zhu, “Design methodology emerged in the 1960s as an independent scientific discipline.” (Zhu 1). The adoption of distributed systems, often spanning several geographical locations and countries with different cultures, has increased the pressure on business analysts, system architects and developers to quickly deliver usable systems in cost efficient manner that serve customers’ needs. Such pressure has more than often led to compromise in software quality, particularly in terms of reliability and correctness as a result of defects leakage from the early stages of project life cycles. According to Patrizio Pelliccione, H. Muccini and N. Guelfi, “The two dominating trends in modern software industry are the increasing complexity and the ever higher dependence of the society on the correct operation of IT systems.” (Pelliccione et al 1). Human beings are social animals and as such we have certain obligations towards our society. We should be careful that none of our actions is detrimental to the society’s interests as a whole. Software technology has a great impact on our society. Owing to this importance of the software technology to the society, the software professionals are bound morally to develop quality products. Poor quality can cause failures and such failures can be dangerous to the society or the people in some or the other manner. According to Sami Beydeda, Matthias Book and Volker Gruhn, “Software is typically not harmful to the environment and can only contribute to violation of safety. Achieving safety is typically ensured by a mix of architural decisions and rigorous process for system development based on functional decomposition.” (Beydeda et al 1). Such failures are strictly discouraged. So, well qualified, skilled and proficient software professionals are engaged in developing economic (value for money), perfect and up-to-the-mark products. Time is also one of the main criteria. The professionals are encouraged to develop the software products on time. There is a sort of global competitiveness in the software industry. According to Hong Zhu, “A wide range of activities are involved in software design. Each activity consists of at least four aspects: the action carried out in the activity, the participants, the input information, and the output or the result of the action.” (Zhu 2). Defect prevention is an essential task in any software project, which should be based on an organized problem-solving methodology to identify, analyze and prevent the manifestation of defects. According to B. Agarwal and S. Tayal, “Most hardware-related reliability models are predicted on failure due to wear rather than failure due to design defects.” (Agarwal 1). Defect prevention is a continuing process of collecting the defect data, doing root cause analysis, determining and implementing the corrective actions, and sharing the findings learned to shun future defects.
The basic part of the defect prevention process should start with requirement analysis which translates customer requirements into product specifications without generating more errors. Next, software architecture is formulated; code reviewed and testing done to observe the defects, followed by defect logging then documentation. According to Steve McConnell, “Testing is the black sheep of QA practices as far as development speed is concerned. It can certainly be done so clumsily that it slows down the development schedule, but most often its effect on the schedule is only indirect.” (McConnell 1)
Overview of Design Defects
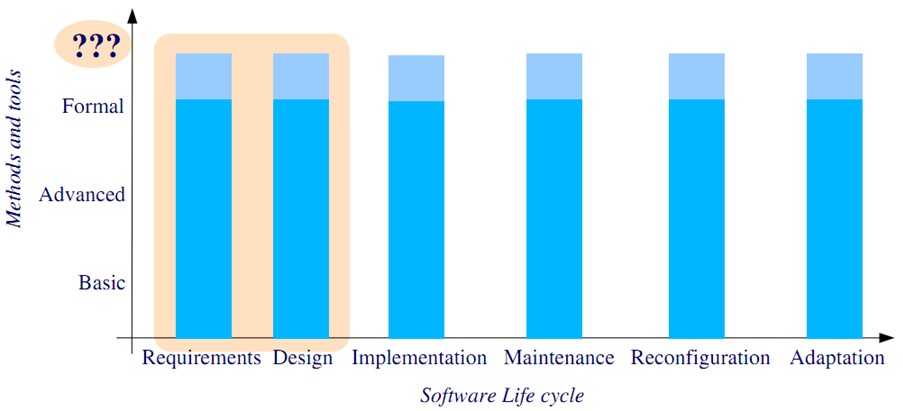
According to Antii Saaksvuori and Anselmi Immonen, “The software industry has been blamed for the fact that it allows mistakes or illogicalities in its products. For some reason, these tend to be called mistakes or illogicalities but software ‘properties’ or ‘features’.” (Saaksvuori 1). Figure 1 is a representation of the life cycle of any particular software. We notice that there is an ambiguity as far as the requirements and designs are concerned. It means that there are no fixed limits for these two factors. Both these factors depend on the market. The arrow shows that there is further scope for both of these factors. The life cycle or the steps to be followed are very simple.
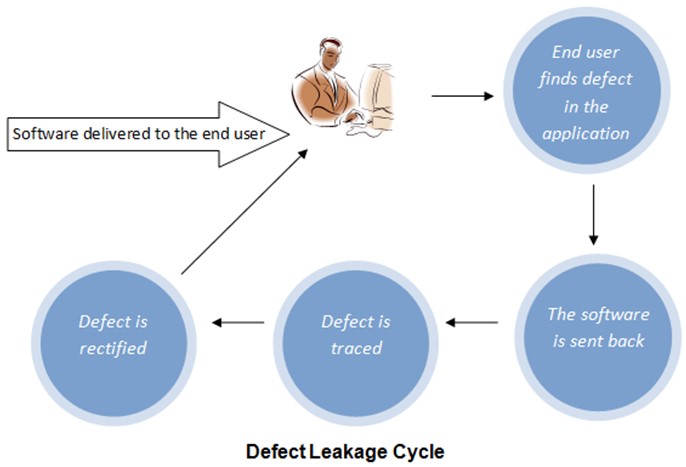
Sometimes, the defect is detected by the end-user. After the software is delivered to the end-user and once he starts using the application, he might find some defect in it. He will revert to the problem. This kind of defect is said to be a defect leakage.
“Software defects are not created equal and exhibit various dynamic behaviors that complicate project decisions.” (Madachy et al, 2011). The major advantage of early defect prevention according to the National Institute of Standard Technology (NIST) in an early [1] that the cost of fixing one bug found in the production stage of software is 15 hours compared to five hours of effort if the same bug were found in the coding stage. Also, according to The Systems Sciences Institute at IBM, the cost to fix a defect realized after product release is four to five times as much as one recognized during design, and up to 100 times more than one realized in the maintenance phases. It is much cheaper to fix defects at early stages, such as requirement, design than at the late stage of testing.
“The software development life cycle (SDLC) (sometimes referred to as the system development life cycle) is the process of creating or altering software systems, and the models and methodologies that people use to develop these systems.” (PTC 1). The various ways and means used in the software development life cycle to identify the source of defects and to avoid the recurrence of such defects is called Defect Prevention (DP). According to the Software Engineering Institute, defect prevention is a level 5 Key Process Area (KPA) in the Capability Maturity Model (CMM). It entails the defects that occurred in the past and based on that, specifies various checkpoints to ensure that such defects don’t reoccur in the future. According to E. Kh Tyugu and Takahira Yamaguchi, “In whatever manner a component is discovered and defined, using the same kind of tactics the error amount of that component in the preceding software is determined. If some past error data from several projects are available, it is only reasonable to make good use of as many of them as possible.” (Tyugu et al 1). Generally speaking, default prevention is a system to propagate the information gathered in between the various projects. “The purpose of defect prevention is to identify those defects at the beginning of the life cycle and prevent them from recurring so that the defect may not surface again.” (Kumaresh et al 1)
Prime information technology companies employ proven software procedures to improve the quality and productivity of their products and also to keep the cost to its minimum. It is evident from Figure 3 that it proves to be a costly affair if there is a delay in the identification of defects.
Figure 3 depicts the rate of defect discovery versus time. “If you can prevent defects or detect and remove them early, you can realize a significant schedule benefit.” (McConnell 2)
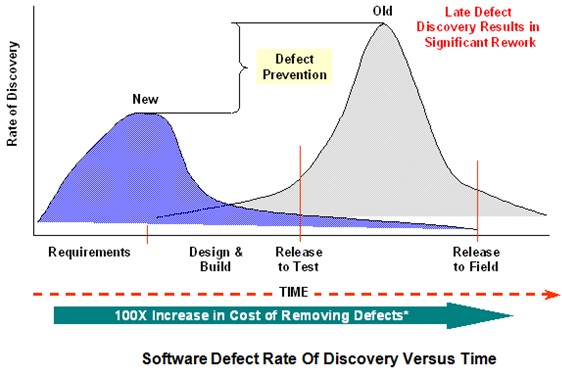
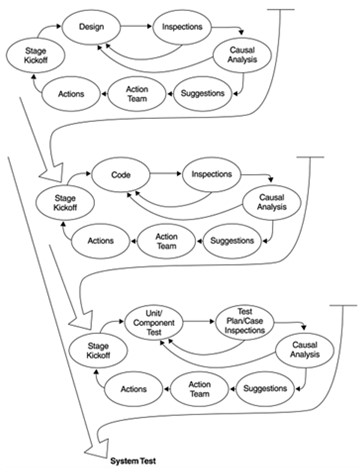
Figure 4, below, shows a typical waterfall model for the prevention of the defects in the software defect life cycle. A better design can prevent the majority of errors. The aim of the software development process should be to produce high-quality products. High-end software is found in every walk of life from the simple mobile phones that we use to complex systems such as navigation systems in aerospace. Software quality is evaluated and enhanced mainly during formal technical reviews, whose primary aim is to detect errors and defects initially in the software process before they are carried forward to another software engineering task or released to the customer. Figure 2 depicts a typical cycle of defect prevention. As such, defects may occur at any stage of the software development life cycle (SDLC). If followed religiously most of the defects can be avoided. Putting his views, Raymondlewallen wrote, “This is the most common and classic of life cycle models, also referred to as a linear-sequential life cycle model.” (Raymondlewallen 1)
“The suggested preventive actions are implemented by rewriting the existing quality manuals and tweaking the SDLC processes and come out with an improved SDLC process and documents.” (Kumaresh et al).
“When a software product has too many defects, developers spend more time fixing the software than they spend writing it in the first place.” (McConnell 3). Software defects compromise the operation of the resultant software system. It is thus a good practice to curb the bugs at an early stage to avoid the resulting weaknesses.
According to Suma V. and T. R. Gopalakrishnan Nair, “There are two approaches for tackling these problems and they are curative approach and preventive approach.” (Suma et al 1). Working with defects inherited from the preliminary periods of design time causes a lot of problems as the debugging becomes cumbersome more so in finding errors that originate from the requirements and design stages. Missing, incomplete or wrong requirements, conflicting requirements, and requirement execution code logic errors, and conflicting code modules can cause great problems and add significant costs to software projects. That is the reason why defects of earlier stages of development must be tracked and removed at the corresponding stages.
“Software defect can be defined as ‘Imperfections in the software development process that would cause the software to fail to meet the desired expectations.” (Kumaresh et al 2). Design defects may be defined as those that are caused by algorithm and processing control, logic, and sequence data. In addition, specifically in distributed systems, such defects may be a result of module interface description and/ or external interface. Such defects may be a result of wrong system component design, overlooked relations between system components, failure for proper analysis description relations between external and internal systems, including both hardware and software. These defects can also be as a result of incomplete and incorrect requirements or as a result of independent injection at the time of design artifacts construction, example would be diagrams of modules, pseudo-code descriptions, algorithms, or data structures.
“Defect removal efficiency originated in IBM in the early 1970s as a method for evaluating testing effectiveness.” (Jones 1). Quality managers and project managers need to identify defects while at the same time engaging a strategy for their classification and elimination that adds value and benefits to the project. These require additional effort and should ensure such add advantage and the required effort achieve unsurpassed cost/benefit which is one of the driving parameters of the project. It is therefore evident that such defects detection and classification should be highly effective and efficient to find a balance between the defect cost and customer detected defects. Bernstein and Yuhas wrote, “The software project manager must invest in these ongoing activities: measuring complexity, measuring effectiveness through investments in tools and technology, and measuring staffing requirements.” (Bernstein et al 1).
“The success of software largely depends on proper analysis, estimation, design, and testing before the same is implemented.” (Kanjilal 1). Various and extensive research work and solutions have been done and proposed in the literature, some of them with their main focus on distributed systems while others focusing on traditional software design in the development cycle. These solutions use tools for the detection and classification of design defects. “Orthogonal Defect Classification (ODC) is the most prevailing technique for identifying defects wherein defects are grouped into types rather than considered independently.” (Kumaresh et al 3). Also, according to Tidwell, “Some of these techniques are very formal, and some aren’t. Formal and Quantitative methods are valuable because they’re good science”. (Tidwell 2).
According to Capers Jones, “Companies that depend purely upon testing for defect removal rarely top 90% in cumulative defect removal, and often are below 75%.” (Jones 2). A number of these solutions demonstrate reasonable levels of precision. Nevertheless, all these tools are based on the ability to detect defects and classify them without diligently factoring in the cost of addressing such defects which therefore calls for a proper classification framework and correct information attachment on the reported defects. It is quite necessary to have a solution developed from the perspective of business requirements rather than only a system perspective.
The analysis of software defects has been in existence for a long time. One of the further common forms is accounting for purposes like an estimation of conclusion time and warranty cost. Another fashionable type of defect analysis is qualitative, that is, to identify the types of errors committed and direct defect avoidance. Stepping back from the diversity of the ways of defect analysis, we can distinguish a broad scale in its practice. According to Kumaresh et al, “Defect analysis is using defects as data for continuous quality improvement.” (Kumaresh et al 4).
Thus, in this research, I aim to endeavor to develop, test, and validation of an algorithm to use within the intellectual framework for purposes of classifying and detecting defects, while at the same time balancing the cost of addressing such defects with business needs, functional needs and other considerations that system developers, designers may need to be catered for the domain of the study is in the design of distributed systems with an emphasis on the creation of tools and framework for efficient and effective defect detection and classification. According to Kumaresh et al, “For small and medium projects, to save time and effort, the defects can be classified up to the first level of ODC while critical projects typically large needs the defects to be classified deeply to get analyze and understand defects.” (Kumaresh et al 5). The derived algorithms will also be tested for soundness and validity, where soundness which has origin in mathematics logic may be described as a deductive system that is true concerning a semantic if it only proves valid arguments. The adoption of intelligent agents is to ensure we benefit from automated, adaptive, and autonomous defect detection and classification. According to Kumaresh et al, “These agents execute tests defined in various algorithms each doing so by various parameter or variables dimension combinations.” (Kumaresh et al 6). However, intelligent agent design defect detection can only be employed if such design is detailed and a proper description for the software modules is at the pseudo-code level with clear and distinct processing steps, data structures with input and output parameters in addition to their major control structures.
All quality measures are relative, therefore, there is no absolute scale upon which we can say A is better than B but it is usually hard to say how much better. The quality of the software is not just understandable to a layman since the software is not manufactured, most of the software is invisible, aesthetic value matters for the user interface, but is only a marginal concern, and one needs to understand the purpose of the software in question. In this way, quality is not an evaluation of software in segregation it is a measure of the connection linking software and its relevance domain may not be capable to measure this until you set the software into its setting and the quality will be dissimilar in different environments. During the design, we have to be capable of predicting how sound the software will fit its intention. Also, according to Kumaresh et al, “The analysis is qualitative and only limited by the range of human investigative capabilities.” (Kumaresh et al 7).
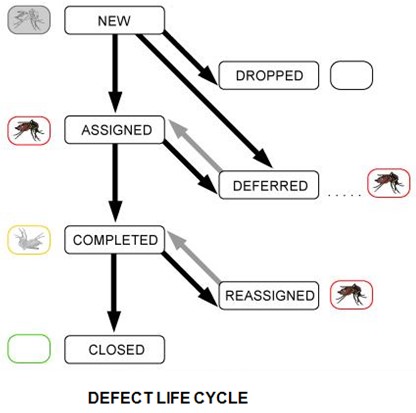
Description of the defect status
- New: When the testing personnel discovers a defect, it is marked as ‘New’. This defect is yet to be categorized. According to Bernstein et al, “The high correlation between defects in the software product and staff churn is chilling.” (Bernstein et al 2). A new defect can be assigned, dropped, or deferred.
- Dropped: If a defect is found to be invalid it is dropped. But the action has to be supported by a valid reason. According to Jeff Tian, “In case that the discovered defect is not corrected, all parties involved must agree on the specific decisions or actions. For example, if a defect from testing is later re-classified as not to be a defect, a justification needs to be given and the decision agreed upon by the person who did the re-classification, the tester who reported it in the first place, and all other people involved.” (Tian 1).
- Assigned: If the defect is found to be legal, a member of the development group is given the task of fixing it and completing it.
- Deferred: If a defect is considered irrelevant to the existing software, it is deferred. This issue is later taken up in the next release of the software.
- Completed: The development personnel fix the assigned defect. This fixed defect has to be verified and this task is done by the test team. According to B. Agarwal and S. P. Tayal, “The key problem for the defect tester is to select inputs that have a high probability of being members of the set I. In many cases, the selection of these test cases is based on the previous experience of test engineers. They use domain knowledge to identify test cases, which are likely to reveal defects.” (Agarwal et al 2). A fixed defect can either be closed (if it is found to be perfect) or reassigned (if still there are some problems).
- Reassigned: if the test team finds that the defect is not yet fixed, it is reassigned to the development group.
- Closed: If the test team finds the defect to be fixed properly, the defect is closed. It should be of importance what K. K. Aggarwal wrote, “Testing can only show the presence of errors. It cannot show the absence of errors.” (Aggarwal 1).
According to Jeff Tian, “Beyond testing, there are many other QA alternatives supported by related techniques and activities, such as inspection, formal verification, defect prevention, and fault tolerance.” (Tian 2)
Guidelines for Defect Life Cycle Implementation
- The whole team should be able to understand the different status of the defects. The defect life cycle should be documented and should be handy for ready reference.
- Every person should understand his/her responsibility and should be able to handle it (about the defect).
- While changing the status of the defect, enough details should be provided so that the person on the next status understands the problem clearly.
- Shortcuts should be discouraged while using a defect tracking tool. Any defect-related request should not be entertained unless the concerned status is changed. In absence of this procedure, the exact defect metrics will not be available.
According to Raymondlewallen, “During testing, the implementation is tested against the requirements to make sure that the product is solving the needs addressed and gathered during the requirement phase.” (Raymondlewallen 1).
Structure of the Report
This report aims at addressing the defects in the software development life cycle process, particularly at the early stages. It is organized as follows: Chapter two provides background information on the defects, explaining why and how they come about and their detection. It elaborates the classifications of these defects into specific categories using the object-oriented approach and the service-oriented architectural approach. Chapter three of this report contains information on the analysis of the defects about the programming paradigms using two approaches namely, the Object-oriented design and the Service-oriented architectural design. It further discusses the architectural level defects and concludes with a proposal for the new classification model for distributed services. In the fourth chapter, a defects tracking model is proposed which takes into consideration strategies that could be applied to reduce software defects tasks. This is based on classification, storage, and intelligent defect pattern detection (neural networks) and how they can improve the efficiency of the tasks. Chapter five concludes the report with suggestions for future work.
Software Defects
Introduction
Software Defect is a term that is used to refer to Imperfections in the software development process that if not checked can cause the software to fail to meet the desired system and the user’s functional and nonfunctional requirements expected of such a system, i.e. as to fail to meet the desired expectations most defects are the result of mistakes and errors made by the development team while developing the programs source code or in requirements and its design. A few errors can also originate from compilers generating code that is incorrect. According to Beydeda et al, “Many kinds of changes must be addressed at all stages of development: errors will be discovered, designs will be updated, requirements will be refined, priorities will be changed, implementations will be refactored, and so on.” (Beydedas 2). The defects can occur in the specification, design, coding, and data entry, and documentation stages of development. According to Hong Zhu, “Software quality must be addressed during the whole process of software development. However, design is of particular importance in developing quality software.” (Zhu 3)
According to Suma, “The existence of defect prevention strategies not only reflect a high level of test discipline maturity but also represent the most cost-beneficial expenditure associated with the entire test effort.” (Suma et al 2). Software defects cannot be entirely done away with but they can be reduced by prevention methods. Such methods include confirming the understanding of software requirements with the customer, working as a team especially in design peer-reviewing, documenting code, and the assumptions made while coding for easy modification, maintaining a checklist that is updated as defects are detected, writing testable code, planning for frequent releases to get feedback, and ensuring code changes do not over complicate the process of testing and debugging. The following diagram depicts the percentage-wise errors before and after testing is done.
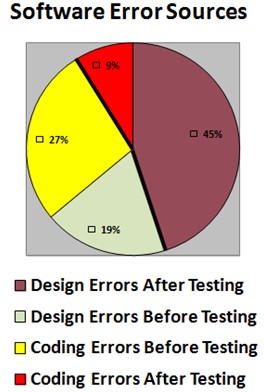
The designing and structuring process of the software is over once the code to be produced is specified in detail, a code-testing plan is formulated and a manual (user’s guide) is made. Usually, for testing purposes, the coding is done on sample software even before the design is finalized and approved. This results in software costs and problems. The above figure shows the percentage of type of errors found in software before and after testing. The yellow and the green portions are the errors found before testing and the red and the brown portions are the errors found after the testing process. The majority of the errors are in the design. Such errors are unable to be detected until the software is tested. In the above figure, it can be noticed that out of the total errors, 46% were before the testing and the remaining 54% were detected after the testing. An important aspect to take note of is that before the testing, the coding errors (27%) were more than the design errors (19%), whereas, after the testing, the design errors (45%) were far more than the coding errors (9%). According to K. K. Aggarwal, “It is advisable to invest more effort in early phases of the software life cycle to reduce the maintenance costs. The defect repair ratio increases heavily from analysis phase to implementation phase.” (Aggarwal 2). Following is a typical defect repair ratio table
Hence, efficient control over the development phase will minimize the cost of maintenance.
Causes of Software Defects
“The root causes of the majority of software defects discovered in integration tests during the development of an embedded system have been attributed to errors in understanding and implementing requirements.” (Bennett 1)
- Human Error: It is the human beings who develop the software and as such, errors are bound to happen.
- Communication failure: Lack of communication or wrong information during the process of software development lead to defects. Such defects can appear at any stage. Suppose the requirements of particular software are not completely mentioned or are unclear. In such situations, errors will occur.
- Unachievable time-frame: Ample time is required to complete any work satisfactorily. Similarly, while developing software also, the developer needs time sufficient time so that he can do his job up to the mark. But it is noticed that software developing companies are in a hurry to launch the software and as such, they want to go ahead of time. This is not practically possible. But since the developer has to do the job in the stipulated time, he does it but is not able to do the code testing (for example) properly, hence leaving defects.
- Lack of domain Knowledge: Most developers are not experts in the business domain served by their applications, be it telecommunications, banking, energy, supply chain, retail, or others hence they end up producing poor quality software. Over time they need to learn more about the domain, but much of this learning will come through correcting defects caused by their mistaken understanding of the functional requirements.
- Lack of Technical Knowledge: Most developers are skilled in several computer languages and technologies. Few developers know all of these languages and technologies, and their incorrect assumptions about how other technologies work is a prime source of the non-functional defects that cause damaging outages, data corruption, and security breaches during operation.
- Poor Design Logic: It happens sometimes that the design of the software to be developed is very complicated. The available time doesn’t allow to research further. So due to the urgency of completion, the software is developed as per available resources and as a result, defects occur.
- Wrong coding: Sometimes, due to bad coding, errors are passed on by mistake. Two-thirds or more of most software development tasks encompass changing or improving existing code. Studies have shown that half of the time spent enhancing existing software is used trying to understand the code. Complex code is usually impenetrable and modifying it causes many errors and unexpected negative side consequences. These introduced defects cause expensive rework and overdue releases.
- Pre-acquisition Practice: Most large multi-tier applications are built and maintained by distributed teams, some or all of whom may be outsourced from other companies. Consequently, the acquiring organization often has little visibility into or control over the quality of the software they are receiving. For various reasons, CMMI levels have not always guaranteed high-quality software deliveries.
- Lack of skilled Testing: It is unacceptable but poor testing happens in most companies. Various factors might be responsible for defects due to this particular reason. Lack of seriousness and unavailability of the required skill are some of the reasons. Poor testing may result in wrong coding, ultimately leading to defects.
- Last-Minute Changes: Changes at the last moment can prove to be hazardous for the software. Such changes might give way to wrong coding and invite defects.
Detection of Defects
From the following figure 7, a clear idea can be had as to how the defects are detected. Software defect prevention is an important part of software development. The quality, reliability, and cost of the software product heavily depend on the software defect detection and prevention process. In the development of a software product 40% or more of the project, time is spent on defect detection activities. According to Bernstein et al, “Most defects originate from simple pair-wise interactions such as, ‘When the font is Arial and the menus are on the right, the tables don’t line up properly.” (Bernstein et al 3). Defects are found by pre-planned activities specifically intended to uncover defects. In general, defects are identified at various stages of the software life cycle through activities like Design review, Code Inspection, GUI review, function, and unit testing. According to Suma V. And T. R. Gopalakrishnan Nair, “There are several approaches to identify the defects like inspections, prototypes, testing and correctness proofs.” (Suma et al 3). Once defects are identified they are then classified using the first level of Orthogonal Defect Classification.
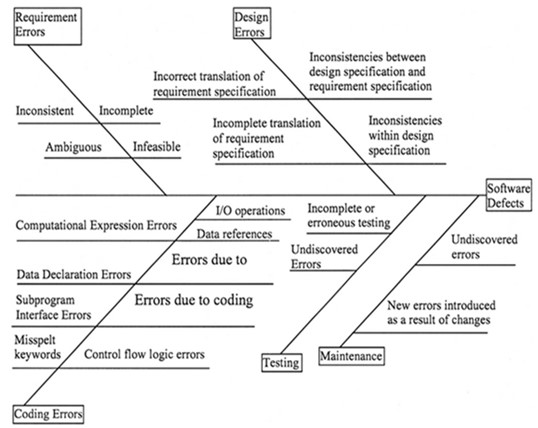
Defect Classification
The term defect can be used to refer to error, failure, or a fault. To be able to prevent, detect and isolate defects a developer needs to understand the meaning of the above terms.
Error is an expression referring to defects in the human thinking process that are made while endeavoring to comprehend given information, to solve problems, or to utilize methods and tools. Based on error we have the following schemes of defects.
- Error origin – this refers to the phase or task in which the misunderstanding occurred. Example subclasses include requirements, specification, design, code, unit test, system test, acceptance test, and maintenance.
- Error domain – by error domain we mean the object or domain of the misunderstanding. Example subclasses include an application (misunderstanding of the problem or application domain), problem-solution (misunderstanding of the solution space), notation in terms of semantics and syntax (are misunderstandings of the semantics of syntax of the notation used to express the problem or solution), environment (misunderstanding of the compiler, operating system or external interface), information management (misunderstanding due to communication) and clerical (a mistyping or misspelling).
- Document error type – this is the form of misunderstanding found in a document. Example subclasses include ambiguity, omission, inconsistency, incorrect fact, wrong section.
- Change effect – Refer to the number of modules changed to fix an error. The fault is a tangible manifestation of errors inside the software. One error may result in several faults and various errors may cause identical faults. Based on this definition we have these error schemes.
- Fault detection time – The phase or task in which the fault was detected. Example subclasses include requirements, specification, design, code, unit test, system test, acceptance test, maintenance.
- Fault Density – Number of faults per KLOC.
- The effort to Isolate/Fix – Refer to the time taken to isolate or fix a fault. It is normally expressed in time intervals.
- Omission/commission – This is where one neglects to include some entity or includes some incorrect statement or fact that is executable.
- Algorithmic fault – Refer to the problem with the algorithm, e.g., control flow (an incorrect path taken), interface (a fault associated with structures outside the modules environment), definition (incorrect definition of a variable or data type), initialization (is a failure to initialize data on entry/exit) and use (is the incorrect use of a data structure, or an erroneous evaluation of the value of a variable) of data.
Failure is a term used to mean differences in the operational software system behavior from user expected requirements. A specific failure may be brought about by several faults and some faults may never fail. This gives little insight into the disparity between reliability and correctness. Based on this we have the following defect schemes.
- Failure detection time –refers to the phase of activity in which the failure was detected. For example, subclasses include unit test, system test, acceptance test, operation.
- System Severity –this is the depth of influence the failure has on the system. Example subclasses include: operation stops completely, the operation is significantly impacted, prevents full use of features but can be compensated, minor or cosmetic.
- Customer Impact –refer to the level of influence the failure has on the customer. Example subclasses are majorly similar to the subclasses for system severity but completed from the customer perspective hence matching failures may be grouped contrarily because of subjective implications and customer contentment issues.
Design Defects
Software designs defects result from poor choices of design which degrade the quality of object-oriented designs. It is these defects that present opportunities for further enhancement. According to W. J. Brown OO Design defects can be defined as wrong solutions to recurring problems in object-oriented designs, characteristically UML class diagrams. They include problems at different levels of granularity, ranging from architectural problems, such as anti-patterns that are opposed to designing patterns to low-level problems, such as code smells which is a symptom of design defects. Code smells are possible symptoms of higher-level effects such as anti-patterns (anti-pattern is described as a design pattern that is normally used although is ineffective and/or counterproductive in practice).
A typical example of a design defect is the Spaghetti Code anti-pattern, which is an element of procedural thinking in object-oriented programming. Spaghetti Code is disclosed by classes that have no structure, declaring long method having no parameters. The names of the classes and methods may suggest procedural programming. Spaghetti Code does not exploit but prevents the use of object orientation mechanisms, such as polymorphism and inheritance.
Reliable systems are often designed with the possibility of component failure in mind, and with repercussions in place to considerably reduce the odds of system failure. It is worth contemplating how engrained the discipline of dependable system design is, outside software engineering. There are two strategies for optimizing a system’s reliability namely: simplicity and redundancy. A simple design is easier to comprehend, test or verify, and easier to operate. The second plan is to take advantage of redundancy. Having a backup of the component or the operation of a system provides for a high probability of operational time.
Potential design defects may be caused by wrong naming conventions, underutilized or over-utilized resources, lack of data, and resource and user protection by failure to define security and privacy or faulty synchronization strategy which may result in data loss through overwriting. Design related defects may be classified as follows:-
User-Interface Defects
These are defects of a system interface where humans interact with the system. They may be caused by the look and feel of the system and/or navigation affecting application usability. The user interface may be a web interface or windows interface. The major criteria to categorize these are the following:
- Missing graphical user interface functionality. This can be traced either by comparing business requirements and design specification documents.
- Misplaced user control, results from the system designer wrongly specifying the wrong UI.
- Wrong data input validation.
- Freezing user interface.
- Wrong components sizes and the wrong color.
These defects can be tested by:
- User Statements: This is a case where a user attempts to understand or communicate exceptions for example inquires about an area showing frustration, confusion, or lack of decision.
- User Inactivity: This happens when a user is not active either on the keyboard or mouse for a long time suggesting uncertainly.
- Toggling: Happens when the user toggles a graphical user interface control for an example dialog box or checkbox indicating confusion.
- Assistance: Happens when the user consults help documentation or online help file, or even calls the service desk for assistance.
- Hit Ratio: This is the difference between the correct hit of user interface action and the wrong one.
Middleware (Business Logic)
Middleware describes tasks and steps used to perform an action specified in user requirement or any other requirement. Also, they can be referred to as business logic since it expresses business rules in distributed systems and services. This service also comprises alteration of data objects either from a data store or messages sent to or from other services. Design defects in this layer are ambiguities in security, missing or wrong business rules and/ or workflows, acceptance of wrong input, or provision of invalid output. Based on this we can group middleware defects as follows:
- Security vulnerabilities. This involves security openings that can be exploited by internal or external attacks. Such defects can cause loss of confidential data which can be used against the organization’s advantage.
- Broken, fault, or missing workflows. For business logic to work effectively, business rules are defined and workflows of data and business processes. If the design doesn’t capture define such adequately and correctly, then flawed processes are developed. This can be a potential cause of faulty and unrepresented business process mapping on the distributed system.
- Inefficient or missing fault-tolerant and recovery strategy. Designers should handle exceptions that may arise such as lost messages, handling errors, message delays, and unresponsive message endpoints.
- Lack of load distribution and fault high availability strategies. This may be missing or faulty.
Backend (data storage)
The focus of this tier is data storage, availability of the data stored, concurrency to avoid overwriting other user or system updates, and security of the information. During the design of distributed systems and services, the medium of storage, the format of data, definition of metadata and their relationships, and development of rules on data retention, archival, and log-ratio should be done. Potential defects in this tier include:
- Missing data storage definitions. This is a result of over-assumption or omission on the definition of an entity, often missing some of the attributes which may later be required by business logic or user interface tiers.
- Lack of proper concurrency and data locking strategy, which either makes updates slow or users overwrite others recorded information.
- Security venerability, data storage should be secure and if this is not captured well in design specification, then loopholes may exist and be exploited by the internal or external environment which may lead to major security breaches.
- Uneconomical use of storage space. Design is supposed to develop archivally and log rotation strategies to save on expensive disk space required for data storage.
Despite this, design defects have not been exactly specified hence there are just a few tools that allow their detection and correction. However, design defects can be systematically specified. After specifying, an algorithm can be automatically generated from the specifications to detect and correct the defects. The detection algorithms are constructed based on metrics, semantically, and structural properties while the correction algorithms are constructed based on refactoring.
Design defects in distributed components and services
Introduction
Component and service-oriented software development aim to offer a radically new approach to the design, construction, implementation, and evolution of software applications. It involves the definition, implementation, and integration of loosely coupled independent components into software systems (Sommerville, 2006). Service-based software applications are assembled and composed of individual services from a variety of sources. The services themselves may be written in several different programming languages and paradigms and run on several different platforms. Most service-oriented architecture is built upon the object-oriented approach, therefore the design stage of SOA applications will involve designing individual components using the OO approach (mainly classes and their relationships), and designing the overall system architecture. Therefore, design defects can occur at different levels which are reviewed in the following sections.
OO Design Defects
An Object-Oriented (OO) design defect is a bad impression of the design mainly because of a violation of one or more design principles. These design principles are known as heuristics and these instructions should be understood as a series of warning bells that will ring when violated. Object-oriented software systems are subject to frequent modifications either during development (iterative, agile are development) or software evolution. In such systems with a large number of classes, detecting design defects can be a complex experience. Bad smells are used to detect design defects in object-oriented software design.
Detection of bad smells enables one to employ appropriate re-factoring to enhance the quality of design. In current bad smell detection systems, bad smells are commonly detected using human intuition, even though recently, people began developing quantitative methods which are effective as they do not include subjectivity (bias) and permit for automation. The quantitative method utilizes the concept design change propagation probability matrix (DCPP matrix) to detect two significant bad smells. The first one is shotgun surgery bad smell and the second one is divergent change the bad smell.
To overcome design defects problems, a method termed DECOR (Defect detection for correction) has been developed and be used to specify methodically high-level design defects and to produce detection and correction algorithms from their specifications nearly automatically. This method presupposes previous work in an integrated process and understanding. It is made of four main stages namely, specification (this entails a specification of defects based on a meta-model to influence them programmatically and store them in a repository of high-level defects.), detection (done by stating techniques and algorithms to detect design defects from the meta-model defined in the specification stage.), Correction( done by refactoring to correct defects detected by identifying initially semi-automatically the alterations to provide for improving the design.) and Validation whereby experimental studies are set up on various programs to help validate detection and correction results. “SDLC is all about stages and phases. Software development is not just creating another program to be used by the general public or a business.” (Geek Interview 1)
Service-oriented architecture design defects
Service-oriented architecture is a way of designing, developing, deploying, and managing systems, in which services provide reusable business functionalities, and software applications are built using functionality from available services. First-class, An SOA infrastructure enables discovery, composition, and invocation of services, with exchange being Protocols are predominantly, but not exclusively, message-based document exchanges. SOA is mainly associated with the web. The design defects can be in the following areas:
- Security: this zone in the application is prone to defects related to the “Access Restrictions”.
- Miscellaneous Data: this zone in the application is prone to defects due to the usage of miscellaneous data such as “single quote” in the search criteria field, “enter key”.
- Unconventional usage of keys: this zone in the application is prone to defects due to the usage of keys in an unconventional way.
All the above defects fall under usual defects which can remain undetected during the design, coding phase
Implications of SOA on testing
The change from traditional methods toward SOA has some risks involved. Many moving parts must function as one closely within constant change. Services have varied characteristics. SOA comes with multiple stakeholders like service providers and service consumers while services have independent lifecycles entwined to how they are developed and maintained. Successful implementations of SOA require that services remain interoperable despite all of the inevitable changes they face. SOA introduces increased complexity to IT, and these complexities center on new associations that need to be managed. There are technical relationships since services depend on infrastructure and applications depend on services. “Some methods work better for specific types of projects, but in the final analysis, the most important factor for the success of a project may be how closely the particular plan was followed.” (Search Software Quality, 2007)
SOA Portfolio Management is the management of that collection of SOA services in which an organization invests (develops, maintains, operates, and retires) to implement its SOA strategy. Sources of ideas for new services may be brought forward by the new Projects, new ideas from any area Legacy system, review/deconstruction/extraction, or analysis of Business Process Maps.
Service-Oriented Architecture (SOA)
According to Arasanjani, Borges, and Holley, SOA is the architectural approach that maintains loosely coupled services to allow business flexibility in an Interoperable, technology-agnostic way. SOA involves a composite set of business-aligned services that support a flexible and dynamically re-configurable end-to-end business processes realization using interface-based service descriptions.
Testing tasks like design, analysis, planning, and execution go on throughout the whole SOA project life cycle. The V-Model is a good test methodology that applies testing discipline through the project life cycle. The project starts with defining the User Requirements. The V-Model suggests that the Business Acceptance Test Criteria for the defined requirements are clear and decided before moving to the onset of the technical design phase. Before moving technical design, the model recommends test criteria distinct for that level of technical requirements, and so on. The V-Model is illustrated below:
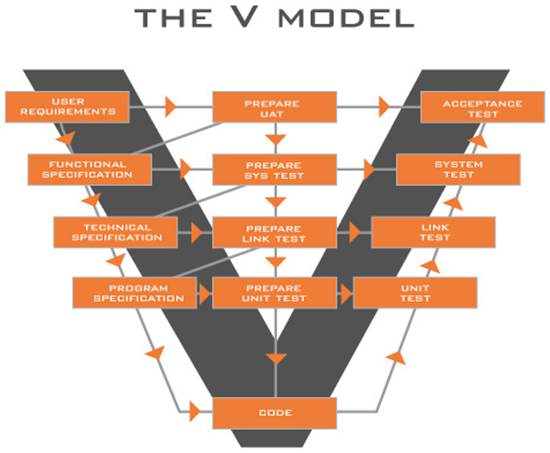
Architectural level defects
Architectural level defects are mainly due to design pattern defects. Design pattern defects can be termed as a sub-category of software architectural defects (SAD) (Naouel Moha, 2005). Design pattern defects are distorted forms of design patterns, i.e. micro-architectures comparable but not equal to those recommended by the solutions of design patterns, also known as design motifs. They also can be termed as occurring errors in the design of the software that results from the absence or the poor use of design patterns. Hong Zhu wrote, “As pointed out by Shaw and Garlan [5], one of the hallmarks of software architectural design is the use of idiomatic patterns of system organization. Many of these patterns have been developed over the years as designers recognized the values of specific organizational principles and structures for certain classes of software systems.” (Zhu 4)
The software architectural defects can be classified into two. Those that help to understand possible types of defects and depending on defect type, debugging methods will be different. These defects can be found at behavioral and structural levels and mainly in functional and non-functional requirements. According to Lawrence Bernstein and C. M. Yuhas, “The distribution of defects is not homogeneous. Defects tend to concentrate in particular areas of the software that are driven by a range of differences in the component complexity, developer’s skill, and the coupling of the software architecture.” (Bernstein et al 4)
Structural defects include but are not limited to syntactic defects, directional defects on connections, flows, missing or unintended connections or flows, date type mismatches, unused components, not matching the architectural pattern used, too much or too little modularity, failure to meet non-functional requirements etc
Behavioral defects include Receive unexpected event, expected event not sent, missing activity, extraneous activity, concurrency issues, execution on incorrect states, pre/ post conditions violations, failure to meet non-functional requirements (ex: performance).
Automated detection and correction of these software architectural defects, which experience a lack of tools, are essential to facilitate the maintenance of service-oriented architectures and thus to minimize the cost of maintenance. A clear understanding of the various types of software architectural defects and the grouping of these defects is important before suggesting any techniques associated with their detection or correction.
Defects Tracking Model
Introduction
According to some researchers, the defect analysis should be done after the testing so that the main reason behind the failure can be detected. According to Lawrence Bernstein and C. M. Yuhas, “An interesting result of defect analysis is that few faults are the result of tester oversight. Using only system requirements and customer documentation would not expose all problems that turn up in the field.” (Bernstein et al 5). In software engineering, defect tracking is the procedure of discovering bugs in a software product by methods like inspection, testing, or recording response from clients, and making new forms of the product that solve the defects. Defect tracking is essential in software development as complicated software systems characteristically contain many defects. To manage, evaluate and prioritize these defects is a tricky undertaking. For this purpose defect tracking systems are used to store defects and help people to cope with them.
New classification model for Defects in Distributed Services
Distributed service-oriented models permit system architects to form a distributed environment in which several applications, irrespective of geographical location, can interoperate absolutely in a platform and language impersonal manner.
This assertion has been made before with the Institution of Distributed Computing Technologies which incorporates proven, widely accepted standards into the integration model, as well as an emphasis on service-based interfaces.
The use of these principles guarantee that applications built and deployed within these architectures will all interoperate absolutely by use of standardized business rules, and all using the same business language.
As illustrated in the RPC-based distributed model with applications and services below, the interpretation of a distributed model starts when new and/or existing applications are opened up for other systems to refer to. This is attained by changing exclusive business application constituents to new application business services based on a standardized XML integration format. Linking several services together can generate new, aggregated services and distributed processes.
As shown in the Figure below, the initial service-based applications will most probably coexist with existing applications using RPC-based communications.
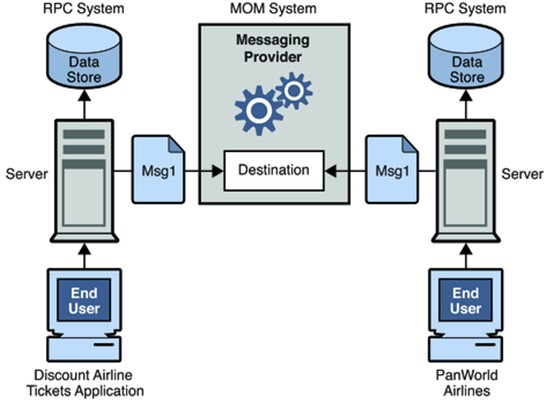
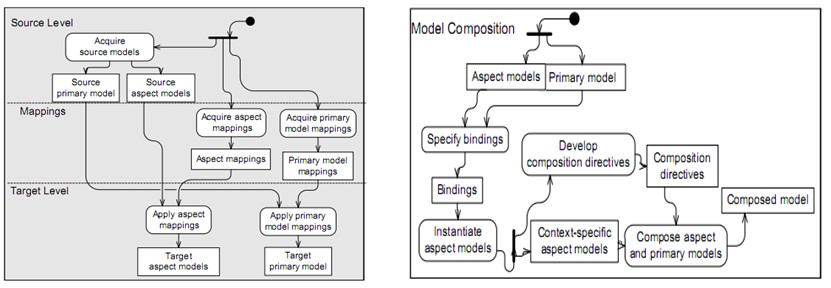
To specify interpretation for general system features that are interlinked with other system features is mostly hard since the elements to be interpreted are distributed across a model. To simplify the separation of general system features and transform their interpretation across diverse levels of abstraction hence easing up communication between services Aspect-Oriented Model-Driven Framework (AOMDF) can be applied.
This model expresses design in terms of a primary model that express the business logic of the application, a group of common aspect models, where each model has a generic expression of a crosscutting characteristic and as a set of bindings that regulate wherein the primary model, the aspect models are to be composed. According to Patrizio Pelliccione, H. Muccini, and N. Guelfi, “Different classes of faults, errors, and failures must be identified and dealt with at every phase of software development, depending on the abstraction level used in modeling the software system under development.” Pelliccione et al, 2007, p.12).
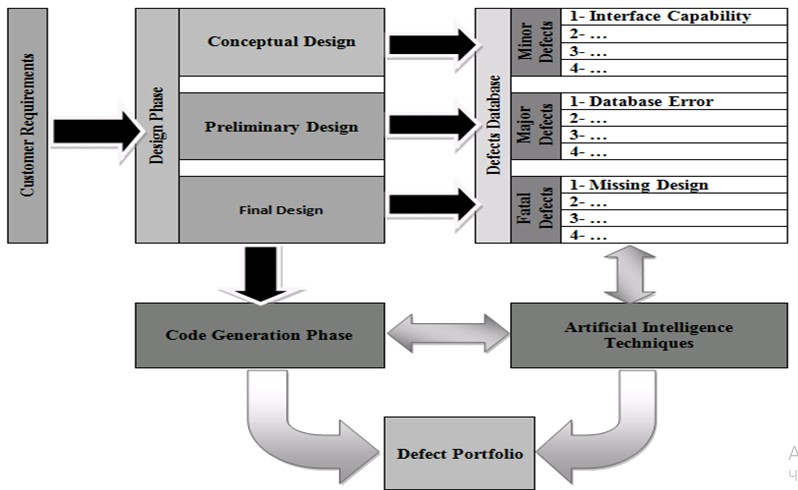
New Design Defects tracking Model
A Defects tracking model helps quality assurance people and programmers keep up to date with reported software defects in their operations. According to Ted L. Bennett and Paull W. Wennberg, “Unfortunately, the methods and tools we use to develop and test systems and software have not kept up with the trend”. (Bennett et al 2). The figure below shows a sample model.
Intelligent Defect pattern detection by use of neural networks
Society depends on telecommunications hence telecommunications software should have maximum dependability. Improved dimension for timely risk examination of latent defects (EMERALD) is aimed at improving the consistency of telecommunications software products. Intelligent Defect pattern detection uses Neural-network models to detect fault-prone components for extra emphasis initially in development, and thus minimize the possibility of operational complications with those components.
Neural Network
This is defined as a massively parallel distributed processor having a natural tendency for storing experiential knowledge and producing it when needed use. It is similar to the brain in that its knowledge is obtained by the network by way of a learning process, and Interneuron connection potency known as synaptic weights that are used to store the knowledge. The illustration below shows a neural network.
Neural Networks is an analytical method modeled after the processes of learning a given software product in the cognitive system and the neurological functions are usually able to predict new observations from others after executing a procedure of so-called learning from existing data.
Conclusion and Future Work
The motive of this report was to outline the defects in software development and the methods of overcoming them. “How the same tests used to verify the system design may be used to verify the controlling software.” (Bennett et al 3) Bennett is true in saying this. My future work will be concentrated on this very aspect. Also, I heard that VSIL is a better system to work on. So I plan to introduce the VSIL system in my future works. This will save me time and will be cost-effective as well. “There are many factors that influence the cost, but a VSIL (virtual system integration laboratory) can be developed for about 5 percent to 10 percent of the overall project cost.” (Bennett et al 4)
References
[Agarwal 1] B. Aggarwal and S. Tayal, “Software Engineering & Testing”, Jones & Bartlett Learning”, 2009.
[Agarwal 2] B. Aggarwal and S. Tayal, “Software Engineering & Testing”, Jones & Bartlett Learning”, 2009.
[Aggarwal 1] K. K. Aggarwal, “Software Engineering”, New Age International, 2005.
[Aggarwal 2] K. K. Aggarwal, “Software Engineering”, New Age International, 2005.
[Bennet et al 1] Ted L. Bennett and Paul W. Wennmberg, “Eliminating Embedded Software Defects Prior to Integration Test”. 2005. Web.
[Bennet et al 2] Ted L. Bennett and Paul W. Wennmberg, “Eliminating Embedded Software Defects Prior to Integration Test”. 2005. Web.
[Bennet et al 3] Ted L. Bennett and Paul W. Wennmberg, “Eliminating Embedded Software Defects Prior to Integration Test”. 2005. Web.
W. Wennmberg, “Eliminating Embedded Software Defects Prior to Integration Test”. Web. 2005.
[Bernstein et al 1] Lawrence Bernstein and C. M. Yuhas, “Trustworthy Systems through Quantitative Software Engineering”, John Wiley and Sons, 2005.
[Bernstein et al 2] Lawrence Bernstein and C. M. Yuhas, “Trustworthy Systems through Quantitative Software Engineering”, John Wiley and Sons, 2005.
[Bernstein et al 3] Lawrence Bernstein and C. M. Yuhas, “Trustworthy Systems through Quantitative Software Engineering”, John Wiley and Sons, 2005.
[Bernstein et al 4] Lawrence Bernstein and C. M. Yuhas, “Trustworthy Systems through Quantitative Software Engineering”, John Wiley and Sons, 2005.
[Bernstein et al 5] Lawrence Bernstein and C. M. Yuhas, “Trustworthy Systems through Quantitative Software Engineering”, John Wiley and Sons, 2005.
[Beydeda et al 1] Sami Beydeda, Matthias Book and Volker Gruhn, “Model-driven Software Development”, Birkhauser, 2005.
[Beydeda et al 2] Sami Beydeda, Matthias Book and Volker Gruhn, “Model-driven Software Development”, Birkhauser, 2005.
[Geek Interview 1] Geek Interview, “Information Technology – SDLC”. 2011.
[Jones 1] Capers Jones, “Predicting Test Cases and Test Team Size”. 2009. Web.
[Jones 2] Capers Jones, “Predicting Test Cases and Test Team Size”. 2009. Web.
[Jones 3] Capers Jones, “Predicting Test Cases and Test Team Size”. 2009. Web.
[Kanjilal 1] Joydip Kanjilal, “Software Development Life Cycle”. 2006.
[Kumaresh et al 1] Sakthi Kumaresh and R. Baskaran, “Defect Analysis and Prevention for Software Process Quality Improvement”. 2010.
[Kumaresh et al 2] Sakthi Kumaresh and R. Baskaran, “Defect Analysis and Prevention for Software Process Quality Improvement”. 2010.
[Kumaresh et al 3] Sakthi Kumaresh and R. Baskaran, “Defect Analysis and Prevention for Software Process Quality Improvement”. 2010.
[Kumaresh et al 4] Sakthi Kumaresh and R. Baskaran, “Defect Analysis and Prevention for Software Process Quality Improvement”. 2010.
[Kumaresh et al 5] Sakthi Kumaresh and R. Baskaran, “Defect Analysis and Prevention for Software Process Quality Improvement”. 2010.
[Kumaresh et al 6] Sakthi Kumaresh and R. Baskaran, “Defect Analysis and Prevention for Software Process Quality Improvement”. 2010.
[Kumaresh et al 7] Sakthi Kumaresh and R. Baskaran, “Defect Analysis and Prevention for Software Process Quality Improvement”. 2010.
[Madachy et al 1] Raymond Madachy, Barry Boehm and Dan Houston, “Modelling Software Defect Dynamics”. 2011.
[McConnell 1] Steve McConnell, “Software Quality at Top Speed”, 1996.
[McConnell 2] Steve McConnell, “Software Quality at Top Speed”, 1996.
[McConnell 3] Steve McConnell, “Software Quality at Top Speed”, 1996.
[Moha et al 1] Moha, Gueheneuc and Leduc, “Bad Smell in Design Patterns”, Journal of the Object Oriented Technology, 2009.
[Pelliccione et al 1] Patrizio Pelliccione, H. Muccini and N. Guelfi, “Software Engineering of Fault Tolerant Systems”, World Scientific, 2007.
[PTC 1] PTC, “Software Development Life Cycle (SDLC), 2011. Web.
[Raymondlewallen 1] Raymondlewallen, “Software development Life Cycle Models”, 2005. Web.
[Raymondlewallen 2] Raymondlewallen, “Software development Life Cycle Models”, 2005. Web.
[Saaksvuori 1] Antti Saaksvuori and Anselmi Immonen, “Product Lifecycle Management”, 2005.
[Search Software Quality 1] Search Software Quality, “System Development Life Cycle (SDLC)”, 2007.
[Suma et al 1] Suma V. and T. R. Gopalakrishnan Nair, “Defect Prevention Approaches in Medium Scale IT Enterprises”, 2008.
[Suma et al 2] Suma V. and T. R. Gopalakrishnan Nair, “Defect Prevention Approaches in Medium Scale IT Enterprises”, 2008.
[Suma et al 3] Suma V. and T. R. Gopalakrishnan Nair, “Defect Prevention Approaches in Medium Scale IT Enterprises”, 2008.
[Tian 1] Jeff Tian, “Software Quality Engineering”, John Wiley and Sons, 2005.
[Tian 2] Jeff Tian, “Software Quality Engineering”, John Wiley and Sons, 2005.
[Tidwell 1] Jennifer Tidwell, “Designing Interfaces”, O’Reilly, 2006.
[Tidwell 2] Jennifer Tidwell, “Designing Interfaces”, O’Reilly, 2006.
[Tyugu 1] E. Kh Tyugu and Takahira Yamaguchi, “Knowledge-based Software Engineering”, IOS Press, 2006.
[Zhu 1] Hong Zhu, “Software design Methodology”, Butterworth-Heinemann, 2005.
[Zhu 2] Hong Zhu, “Software design Methodology”, Butterworth-Heinemann, 2005.
[Zhu 3] Hong Zhu, “Software design Methodology”, Butterworth-Heinemann, 2005.
[Zhu 4] Hong Zhu, “Software design Methodology”, Butterworth-Heinemann, 2005.