Introduction
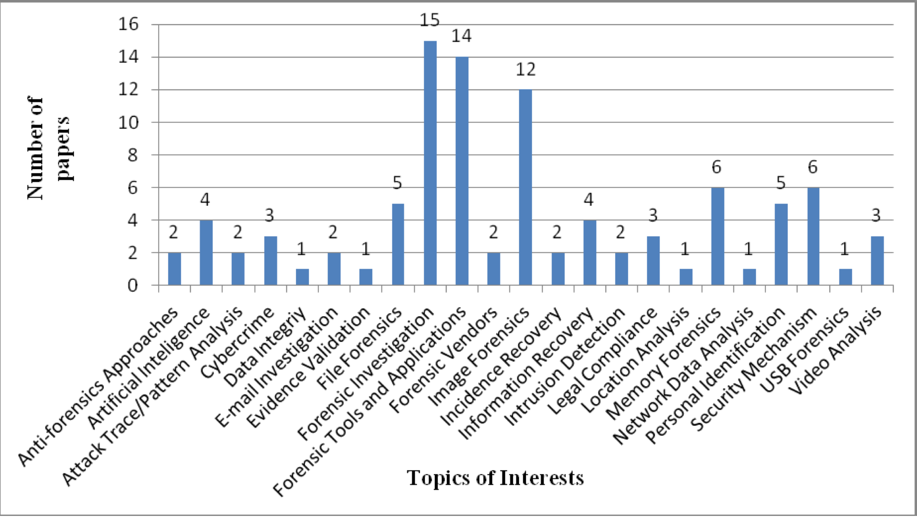
When designing local networks’ IT architecture, whether it is a large enterprise, a small company, or a home network, security is a key performance criterion. Protecting networks from outside interference, regular checks, and optimizing computational processes and node links are priorities for creating a quality system. Nevertheless, it is essential for a competent professional not only to develop skills to form a fully protected network but also to be able to extract data from sources, which can be helpful in legal proceedings and the creation of evidence. These competencies fall under the category of digital forensics, the basic definition of which includes the processes of preserving, identifying, retrieving, and documenting computer evidence (Arnes, 2017). Thus, this branch of computer science is focused on finding open platforms and points of vulnerability that allow the extraction of valuable data in the field of criminal actions. These areas show increased popularity (Figure 1), and therefore their research is important. Hence, this research article seeks an in-depth discussion of digital forensics in the context of analyzing the steps and tools that are used to.
Digital Forensics Methodology
It is of paramount importance to recognize that digital forensics’ science emerged relatively recently in response to increased social demand for the use of computer technology to solve criminal cases more effectively. It seems evident that the widespread use of digitalization has eventually reached the judiciary, but this science’s relatively young age corresponds to the lack of a coherent theoretical framework per se. Many of the world’s core laboratories are not only developing their own forensic methodologies but also providing unique definitions for the term (Fruhlinger, 2019). This section discusses the most general structure for working with extracted data, designed according to the NIST model.
A discussion of the goals pursued by experts in digital forensics should precede a detailed presentation of processing. Specifically, the field, which was created by integrating forensics and computer science, has six key goals. The first is to recover, preserve, and analyze digital materials in such a way that they can be used as evidence in court. The second is to identify the motive for the crime and the identity of the perpetrator. The third goal of digital forensics is to develop crime scene procedures that determine the extent to which digital evidence is corrupted. From the first goal comes the ability to collect and copy by restoring them from deleted libraries for later verification. Then, forensics allows the investigation of the retrospective of crimes by tracking web server logs and session times. Finally, this field’s ultimate goal is to create visually appealing and accessible computer forensics reports summarizing all steps of investigations.

The digital forensics methodology’s critical elements meet the properties of consistency, consistency, and continuity of results (Figure 2). More specifically, the first step characterizes computer equipment preparation for examination (“Forensics fundamentals,” 2021). Because the devices used must have high reliability and sensitivity, it is the examiners’ task to update the software regularly and use only the equipment necessary for the specific task. Nevertheless, the preparation phase also includes bit-by-bit copying of the investigative material previously obtained during the judicial inquiry. It is important to note that this procedure is required to maintain an absolutely identical copy of the original data without adding or removing any bits (Carroll et al., 2017). Thus, interaction with the original data should be kept to a minimum, and any checks should be performed on the forensic image. In doing so, any vulnerabilities or copying errors can be detected through hashing or digital fingerprint verification.
The next step in digital forensics methodology is data extraction, and it can be done in two ways: physical and logical. Physical extraction involves complete extraction at the physical level without regard to specific file systems: it is the process of creating a complete image followed by detailed processing (“Digital forensics,” n.d.). This method uses keywords or specialized software that helps the examiner scan the physical disk (Carroll et al., 2017). Logical extraction consists of critically examining the disk’s file system to find hidden reserves, deleted data, and active files. This variant is characterized by comparative analysis of computed and authenticated hash values, targeted file search, and extraction of password-protected data.
One of the critical phases of the methodology is the identification of detected material. This procedure is based on examining the library of collected files to determine their applicability to a particular forensic query. Thus, if the data array is not helpful for the case, it is marked as processed and irrelevant. Notably, during identification, an expert may discover criminal data that the perpetrator was not suspected initially of having. In such a case, the best strategy is to terminate the search and request the appropriate order from law enforcement. In addition, the examiner may conclude that a certain amount of material may be located on external media: USB or CD. In such a case, the examiner may petition for new evidence admission, which has not been discovered before.
The final phase of the digital forensics methodology is data analysis, characterized as a complete synthesis of the collected data and report preparation. This stage is the most important in terms of proper appeal to the court because the summation’s quality directly determines the outcome of the examination. It should be understood that judges and juries are rarely familiar with professional computer terms, and therefore the analysis report should be as accessible as possible. Thus, the critical criteria of the analysis stage are to discuss the significance, relevance, and importance of the procedures performed and the results collected.
The Use of Digital Forensics Tools
In a mature market for computer technology, it seems inappropriate to use manual labor to independently collect, examine, and analyze data processed as part of a forensic investigation. Manual monitoring of collected data has several critical disadvantages, including processing time, final quality, and the potential for related errors. In contrast, the use of specially designed platforms can prevent such threats and significantly improve digital forensics’ quality and reliability.
One of the first standard tools is FTK® IMAGER, which is a mechanism for the preliminary monitoring of information from file systems. This tool has several key functional advantages, among which special attention should be paid to the possibilities of fast data processing and visualization so that the examiner can determine the appropriateness of further investigation (“FTK® IMAGER,” n.d.). In addition, FTK® IMAGER also creates entirely identical forensic images of the originals without making any changes. Other advantages of using this software include the breadth of applicability — analysis of XFS, APFS images — the ability to recover deleted data, fast examination speed, and the use of hashing mechanisms to verify data integrity via MD5 or SHA-1. Finally, FTK® IMAGER is a constantly updated system that supports the most current investigative protocols.
Another notable digital forensics tool is EnCase® Forensic, traditionally used to recover evidence in seized electronic media. This software has several crucial advantages, including the ability to fragment complex file structures into cells for further investigation: registry files and dbx and pst, thumbs.db files. In addition, the functionality of EnCase® Forensic includes the use of a timeline capable of clearly illustrating the sequence of the criminal’s actions (“EnCase® Forensic,” n.d.). In addition, an expert using this platform can create automatic scripts for report generation, file clipping, or decryption. Thus, these tools, combined with other competitors, present the user with increased functionality to save personal time and conduct more reliable investigations. Thus, their use is fundamentally essential for streaming forensics in digital forensics.
Digital Forensics Hashing
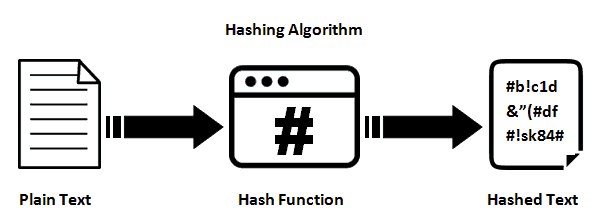
It should also be noted that the use of hashing function is a prevalent practice in digital forensics. In general, hashing should be understood as a cryptographic mathematical algorithm that converts the original array of data into a bit string consisting of letters and numbers of a fixed length, as shown in Figure 3 (Chang et al., 2019). The relevance of using this function increases when the investigation object is a hard disk with a large number of files, their fragments, copies, and settings distributed unevenly throughout the system’s directories. In this case, the real forensic interest is only part of this array, so using a set of hashes allows categorizing the available materials. In particular, hashes of known files or files included in serial software of different manufacturers allow, without examining in detail the content of these files, to discard them and be sure that they do not contain user information. Thus, the exclusion of a considerable number of irrelevant files allows you to reduce the sample for examination significantly.
Nevertheless, it is worth noting that attackers can bypass the hashing procedure. In particular, since there is a direct link between the bits of the file and the output hash value, any modification of the former cause legitimate modifications to the latter. Thus, criminals can deliberately replace some of the primary sequence elements to hide the hashes from detection software. In addition, any damage to portions of the file also prevents the hash function from triggering efficiently.
The Importance of Data Reliability
In order to perform reliable digital forensics, it is critical to ensure the reliability of the data collected. Situations in which seized materials are found to be compromised and tampered with must be avoided, as this has the potential to disrupt the fairness of the court. Thus, digital forensics must take care of mechanisms to protect collected files from tampering (Schneider et al., 2020). Secure programming strategies that protect electronic devices from attacks from external sources (“Secure programming fundamentals,” 2021) are appropriate to realize this goal. More specifically, one such tool is input validation, which prevents incorrectly generated data from entering the laboratory information system. Traditionally, the responsibility for such validation has been part of the functionality of software used for forensics. Specifically, applications should verify and automatically validate all data entered into the system. This procedure can be implemented using programming languages that automatically perform input validation, be it Java and C#. Otherwise, manual configuration of criteria for validating incoming data is necessary.
There are also alternative reliability control mechanisms that can ensure the security of the data being collected. First of all, it concerns the access control system, which implies the inability to manipulate the materials of those employees who do not have a sufficient level. Such a strategy will allow for introducing a system of accountability and a quicker response to cases of data breaches. In addition, it will prevent unauthorized entry into the information system to change code. The use of malware-tracking platforms is also significant because it allows automatic management of system security. Finally, another preventive method of protection is the preliminary analysis of threats and remediation strategies.
The Laboratory Work
The purpose of this laboratory work was to learn more about the practical implementation of digital forensics and to identify weaknesses that need to be covered by the study of theory. Specifically, the typology used for the work was as shown in Figure 4. Four types of virtual machines were proposed, among which two played the role of target devices, and two played the role of attackers. The FTK® IMAGER environment was used as the forensic tool used. The work involved two sequential tasks. The first focused on creating an image of the directory on the virtual machine (Figure 5), and the second on verifying the created image (Figure 6) and implementing the forensic elements.

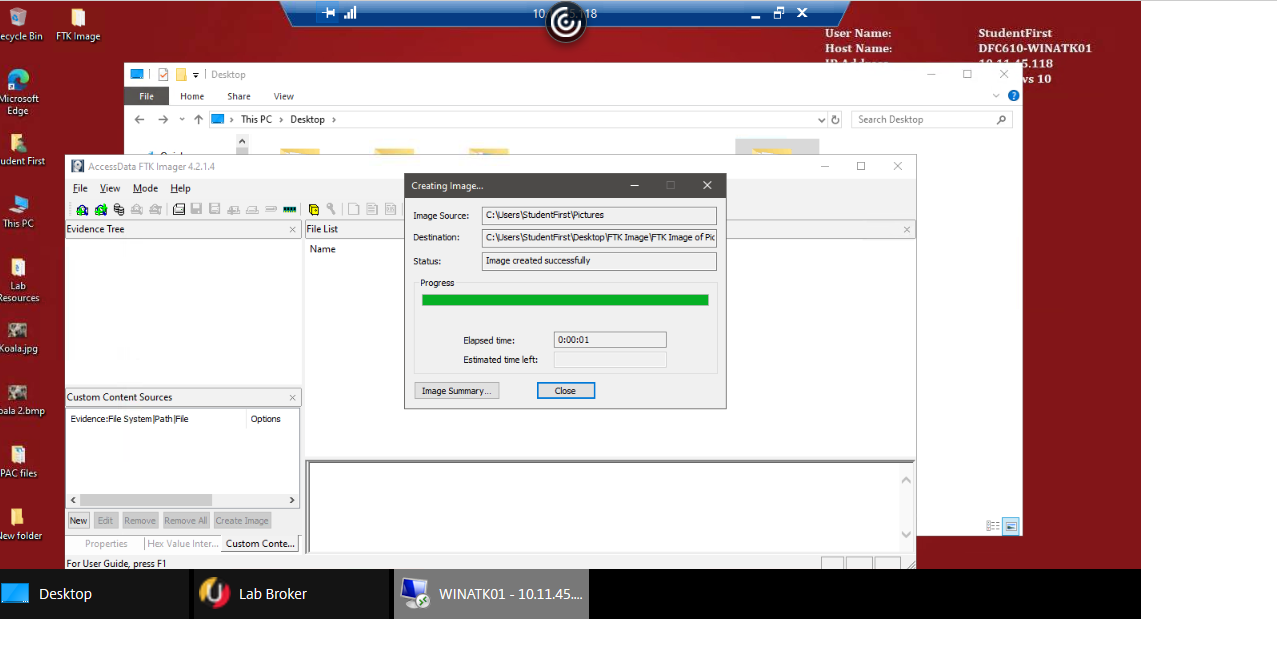
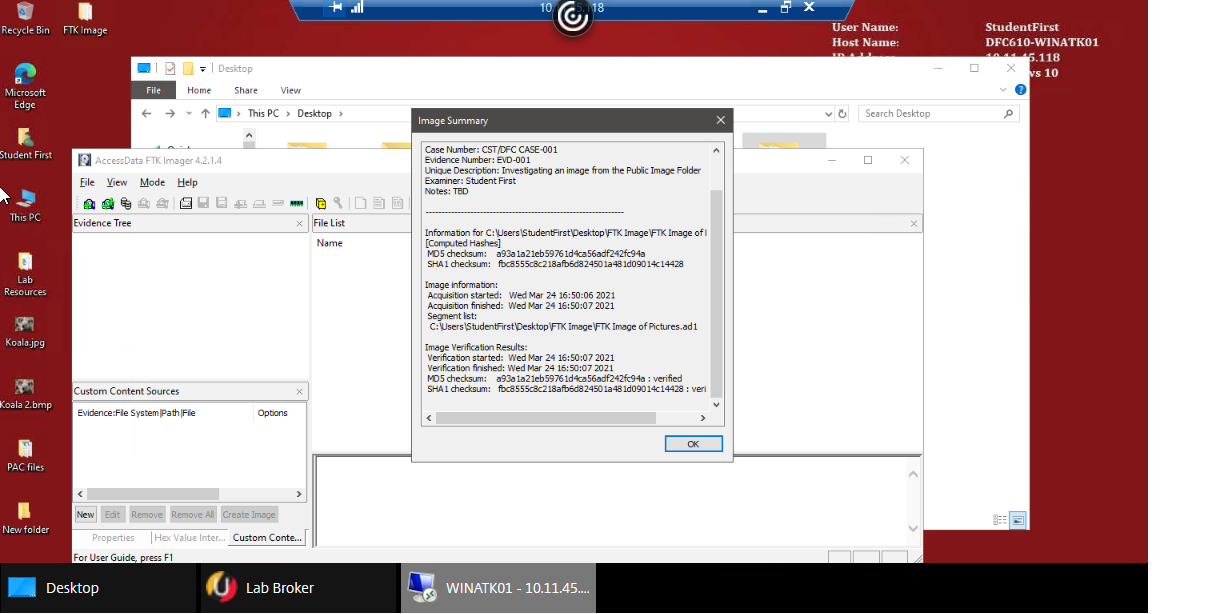
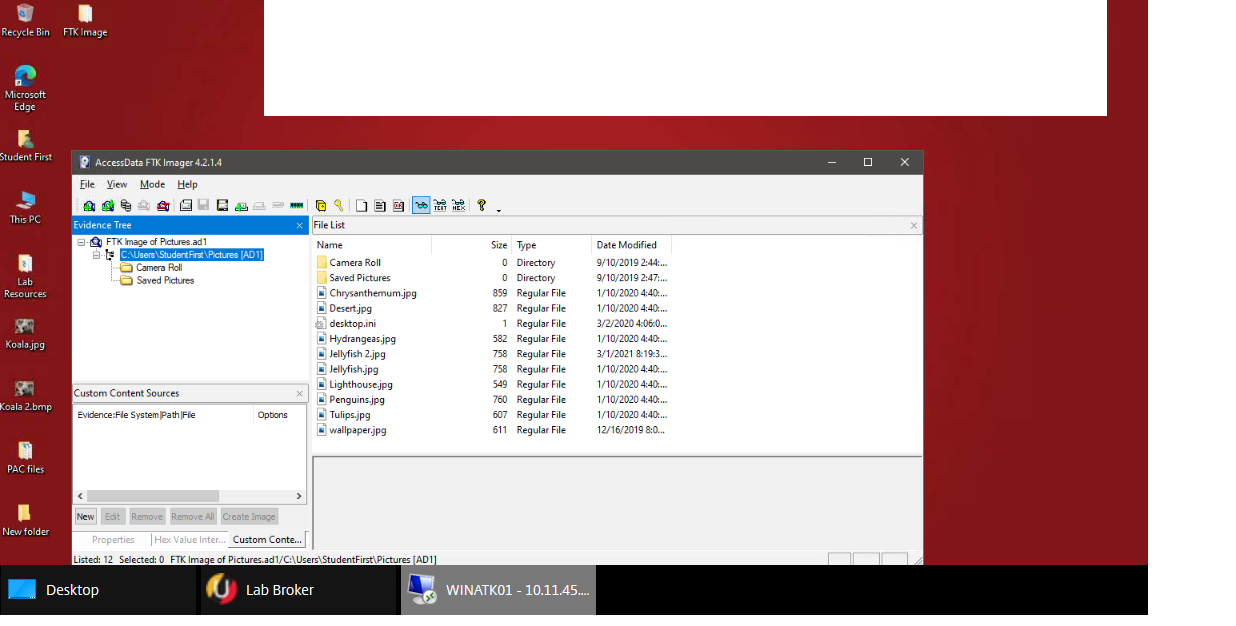
Thus, as a result of this work, the following results were achieved. First, an introduction to the functionality of FTK® IMAGER was made. Second, an image of the required directory was successfully created. Third, it was shown that the image could be examined with FTK® IMAGER, and the image sought could be detected. Consequently, the laboratory showed the success of the practical implementation of the theoretical knowledge in digital forensics.
References
Arnes, A. (2017). Digital forensics. John Wiley & Sons.
Carroll, O. L., Brannon, S. K., & Song, T. (2017). Computer forensics: Digital forensic analysis methodology [PDF document]. Web.
Chang, D., Ghosh, M., Sanadhya, S. K., Singh, M., & White, D. R. (2019). FbHash: A new similarity hashing scheme for digital forensics. Digital Investigation, 29(1), 113-123.
Dezfouli, F., & Dehghantanha, A. (2014). Digital forensics trends and future. International Journal of Cyber-Security and Digital Forensics (IJCSDF), 3(4), 183-199.
Digital forensics. (n.d.). N5 Computer Science. Web.
EnCase® Forensic (n.d.). OpenText.
Forensics fundamentals. (2021). University of Maryland Global Campus. Web.
Fortuna, A. (2020). Digital forensic basics: An analysis methodology flow chart. Andrea Fortuna.
Fruhlinger, J. (2019). What is digital forensics? And how to land a job in this hot field. CSO.
FTK® IMAGER. (n.d.). Access Data.
Hashing algorithm (2020). Network Encyclopedia.
Schneider, J., Wolf, J., & Freiling, F. (2020). Tampering with Digital Evidence is Hard: The case of main memory images. Forensic Science International: Digital Investigation, 32, 1-20.
Secure programming fundamentals. (2021). University of Maryland Global Campus. Web.