It is very vital in statistics to ensure that statistics test assumptions are met, different test statistics have diffeassumptionsption wish are based on the test being carried out. The assumptions ascertain that the result obtaobtained isnot biased in any way, this ensures the tests are reliable, objective, and accurate. They also allow the tests to be carried out in controlled experiments, facilitating comparison and the tests they to be carried out, as it is impossible to consider all variables involved in a test objectively (Weinberg, 2008, p. 690). Failure to adhere to the assumption renders the test to be bias, inaccurate, and not being objective toward the experiment being carried out.
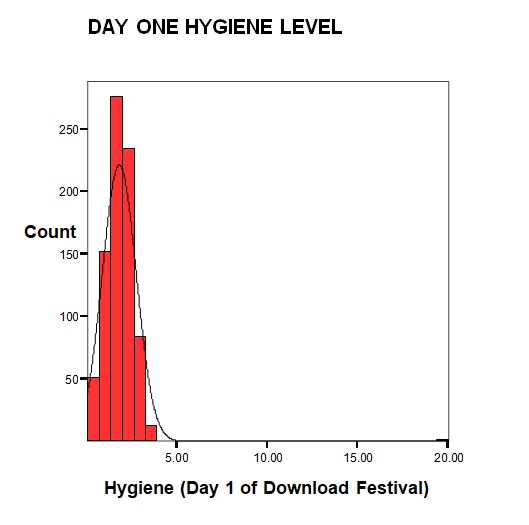
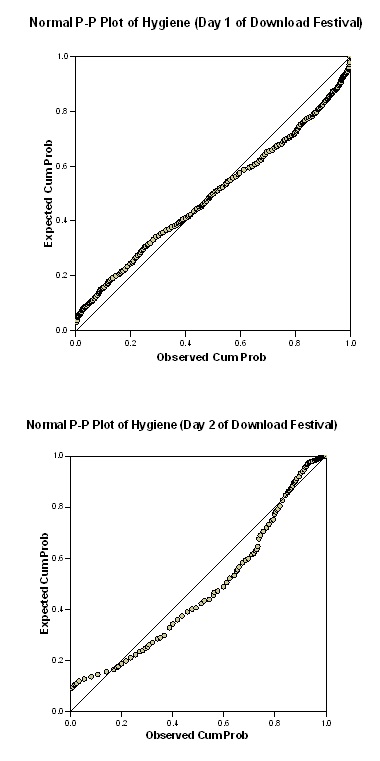
Day one hygiene is normally distributed from the bell shape of the normal curve plotted in the histogram. Also from the p-p curvet, the expected cumulative probability is almost equal to the observed cumulative probability, thus concluding the data set is normally distributed.
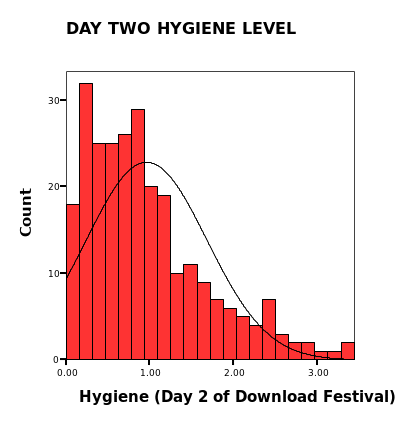
Day two hygiene data set is not normally distributed as the normal curve plotted in the histogram is skewed to the right. Also from the p-p curvet, the expected cumulative probability varies a lot from the observed cumulative probability.
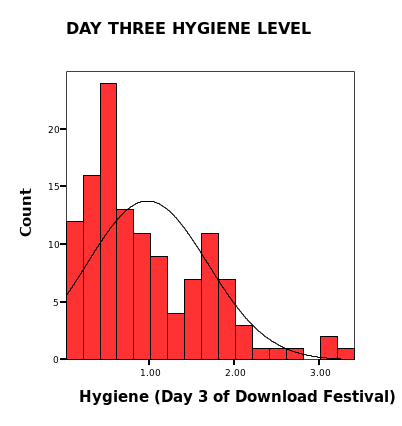
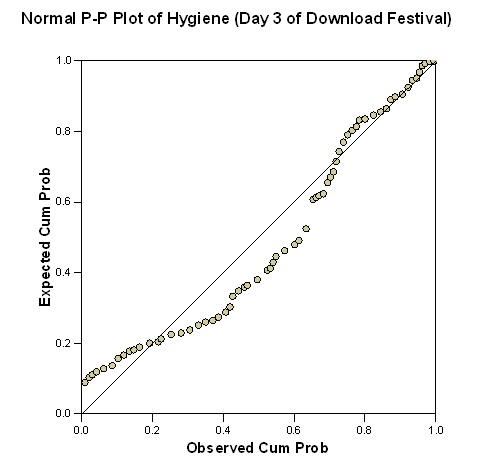
Day three hygiene data set is not normally distributed as the normal curve plotted in the histogram is skewed to the right. Also from the p-p curve, the expected cumulative probability varies a lot from the observed cumulative probability.
Standard Descriptive Statistics for Hygiene Data Set.
Day one hygiene computation results are mean =1.7934, median =1.7900, and mode =2.0, the descriptive statistic are approximately all equal Skewness is computed to be 8.865 implying the data set is asymmetric. Kurtosis is computed to be 170.450 implying a possibility of leptokurtic distribution. There is large variation in the data set; range = 20 and variance =0.892. From the computational result of the data set, normal distribution assumptions are not met, hence the data is not normally distributed
Day two hygiene data has a large variation between the mode, me, and, theme values (mean =0.9609, median =0.7900, mode =0.23). Skewness is computed to be 1.095 implying it is approximately symmetric. Kurtosis is computed to be 0.822 implying a possibility of mesokurtic distribution. There is a small l variation in the data set; range = 3.44 and variance =0.520. From the computational result of the data set normal distribution assumptions are met, hence the data is normally distributed
Day three hygiene data set has a large variation among the mode, mean and Indian values (mean =0.9765, mode =0.7600, median =0.44). Skewness is computed to be 1.033 implying the data set is approximately symmetric. Kurtosis is computed to be 0.732 implying a possibility of mesokurtic distribution. There is a small variation in the data set; range =3.39 and variance =0.504. From the computational result of the data set, normal distribution aassumptionsnsre met, hence concluding the data is normally distributed.
The results from computation are opposite of the observed results, this shows the subjective nature of results derived from observation
Standard Descriptive Statistics for Exam Data.
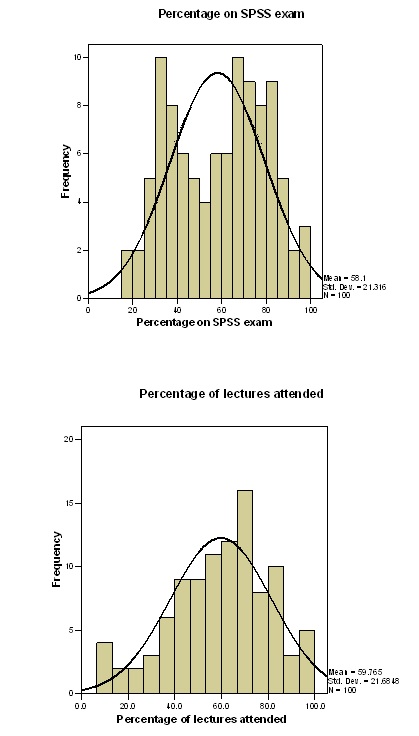
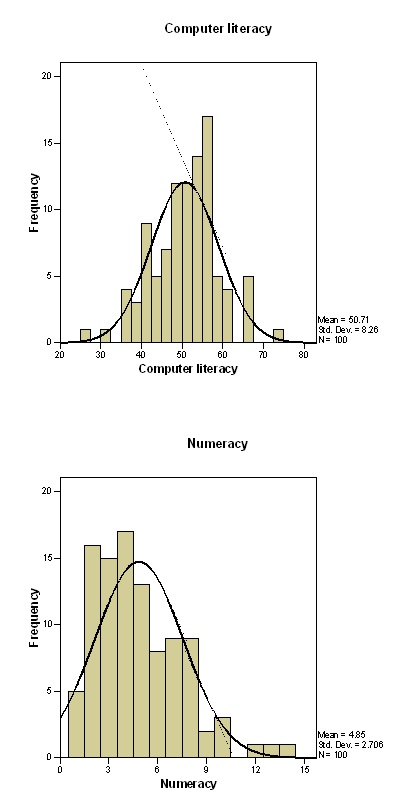
The descriptive statistics from the computation of the data set for the computer literacy, percentage of lectures attended and percentage on spss exam have met the normal distribution assumptions. Based on the results of skewness is approximately close to zero, kurtosis is in the range of -3<k<3, and means, mode, and median are approximately equal. The numeracy data set do not meet the normal distribution assumption hence not normally distributed, based on skewness, kurtosis, and central tendency descriptions from computation (Landau, 2004, p. 272).
The Levene test significance value is 0.801 for computer literacy, hence the result for assumed equal variance for the groups is used to analyze the results. The t-test significance value is -0.543 and the mean difference confidence interval does not contain a zero, this indicates a significant difference between the two universities. This leads to the conclusion that computer literacy between Duncetown University and Sussex University is significantly different.
The Levene test significance value for lectures attended percentage is 0.191, hence the result for assumed equal variance for the groups is used to analyze the results. The mean difference confidence interval does not contain a zero; this indicates a significant difference between the two universities. This leads to the conclusion that the percentage of the lectures attended between Duncetown University and Sussex University are significantly different.
The assumption of normality assumes that the mean of different samples from the same population are equal and also equal to the mean of the population itself. Homogeneity of variance assumes that when comparing the variance of two populations based on their mean, the variance should be equal or variability between variables in two different populations is the same (Weinberg, 2008, p. 553). If the assumption of the homogeneity of variance is violated, a statistician may turn to other inference drawing techniques about the population mean comparison without impacting on the intended result. Ranked data technique may be used in case normality assumption is not observed without any impact on the desired result (Landau, 2004, p. 301). Degree of freedom correction methods may be used in case assumptions of variance homogeneity are violated without impact on desired results. Alternatively, the course of action is simply written “Proceed with caution”, this declares the statistician proceeds with t-test with caution as the assumption is violated.
Reference List
Landau, S. (2004). A Handbook of Statistical Analyses Using SPSS. New York. Barnes & Noble.
Weinberg, S. (2008). Statistics using SPSS: An Integrative Approach. California. Wadsworth Publishing.